🇫🇷 Trading simulator conception
Ce travail a été fait avec Gaëtan BLOND, Alix CANDUSSO, Marc DAMIE dans le cadre de l’UV LO21.
Tout l’enjeu de ce document sera de présenter les choix effectués en appuyant toujours sur ce qui rend nos choix péreins dans le sens où ils produiront un code maintenable, modulaire et simple à faire évoluer.
Nous ne rentrons que rarement dans des détails techniques et seulement si le côté technique traduit un choix d’implémentation significatif. Le côté technique et programmation sera réservé à la documentation jointe à ce rapport. Nous parlerons donc de conception plutôt que de programmation. Ainsi, nous éviterons au maximum de faire apparaître du code C++ dans ce document.
Afin de ne jamais nous perdre dans des explications trop longues, nous privilégierons autant que possible le recours à des UML (toujours commentés évidemment).
Le contexte
Pour l’utilisateur
Le but du projet était de réaliser un logiciel permettant la visualisation de cours et la simulation de sessions de trading. L’utilisateur pourra importer l’évolution d’une ou plusieurs cotations dans le logiciel. L’évolution d’un cours devra être stockée sous la forme d’un CSV. Bien que le programme ait un porte-monnaie virtuel pouvant comporter plus de deux monnaies et qu’il peut retenir l’évolution de différentes cotations, la simulation ne pourra porter que sur une cotation à la fois. Cependant, ces fonctionnalités déjà implémentées pourront être adaptées. Par exemple, dans le futur, la stratégie de décision pourrait prendre en compte plusieurs cours en parallèle. Un autre objectif de ce projet était de pouvoir prendre quelques notes d’une stratégie et de pouvoir faire un import/export de celle-ci avec toutes les données qui y sont liées.
Notons que lors de l’importation de CSV, l’utilisateur sera invité à définir quelques paramètres de simulation: le montant initialement possédé de chaque devise concernée, la taxe du broker et évidemment le code des deux devises.
A tout moment, l’utilisateur pourra passer de la visualisation du graphe de bougies d’une cotation à une autre.
L’utilisateur pourra visualiser à tout moment: le montant qu’il possède de chaque monnaie, les informations (Open, Close, High, Low, Volume, Pattern et indicateurs) d’une bougie sur laquelle il clique, un graphe des bougies de la cotation courante et le graphe de l’évolution du volume de cette cotation. Sur ces deux graphiques, il sera possible de zommer et de dézoomer sachant que l’évolution peut parfois s’étendre sur plusieurs années.
L’utilisateur pourra également choisir une bougie et lancer une simulation manuelle ou automatique à partir de cette bougie. Il pourra tout à fait annuler les dernières transactions qui ne lui conviennent pas.
Un tableau des dernières transactions est également présent pour faire un bilan financier des derniers événements.
Sachant que nous ne sommes pas des experts de la finance, nous avons essayé de fournir des visualisations précises et complètes avec une disponibilité du maximum d’informations pour l’utilisateur afin qu’il puisse faire ses propres choix de stratégies potentiellement bien meilleur que ceux de notre “IA”.
Pour le développeur
Nous n’avons pas eu le temps d’implémenter certaines fonctionnalités à leur plein potentiel mais nous avons tout au long du code essayé d’avoir quelques principes de développement (coûteux temporellement) afin de s’assurer que le code puisse être repris et compléter par un développeur tiers:
- Modularité: nos fonctions doivent quasiment toutes être développées dans une idée modulaire. Les fonctions doivent être aussi indépendantes que possibles du reste du code. Il faudrait pratiquement que nos fonctions soient utilisables directement dans le code d’un autre groupe.
- Les fonctions doivent répondre à des besoins conceptuels et non pas à un usage direct. Une fonction doit répondre de manière la plus générale possible aux besoins même si toutes ses potentialités ne sont pas exploitées dans le projet dans son état actuel. Ainsi, le travail futur d’ajout de fonctionnalités sera simplifié car il n’y aura qu’à ajouter des fonctions; les fonctions existantes étant poussées à leur plein potentiel elle n’auront besoin d’aucune modification. Le fait d’éviter de modifier des fonctions existantes est central pour l’amélioration continue car cela évitera au programmeur de devoir se plonger dans l’esprit de son prédécesseur en essayant de comprendre chaque détail d’un code qu’il n’a pas produit.
- Utilisation maximale des types propres à Qt pour des questions d’optimisation et de fonctionnalités supplémentaires que possèdent ces types (en remplaçant par exemple
std::stringparQString). - Nomenclature des attributs et des méthodes:_nom pour les attributs de la classe, getValue (camelCase) pour les méthodes et ClassExample(début majuscule et camelCase) pour les classes.
- Pas d’allocation dynamique brute : on utilisera des
unique_ptretshared_ptrce qui évitera des fuites de données lors d’utilisations modulaires de nos fonctions. - Se documenter au maximum pour avoir recours autant que possible à des design patterns. Dans ce rapport, nous ne mettrons pas en avant l’utilisation des design patterns les plus simples tel que l’itérateur (souvent intégré nativement dans les types qu’on utilisera).
- Privilégier de la qualité à la quantité. Nous avons favorisé le développement de fonctionnalités propres et débuguées plutôt que de produire le maximum de fonctionnalités mais toutes avec des problèmes de fonctionnement et de conception. Cela est nécessaire dans une démarche de développement continu d’un logiciel car il est bien plus difficile de corriger un code défaillant que de compléter des codes propres à l’aide de nouvelles fonctions.
Architecture: choix et justifications
Au fur et à mesure de la description de notre architecture, nous justifierons les choix un à un. Nous considérerons que cela permettra d’envisager plus facilement notre architecture que si nous séparions en deux axes description et justification.
Afin d’illustrer nos différents choix de conception, nous produirons des diagrammes. Nous avons fait le choix de ne jamais produire un diagramme de l’ensemble du logiciel. Nous effectuerons systématiquement des diagrammes des éléments qui concernent la fonctionnalité dont nous parlerons. Au début du projet, nous avions produit un UML de l’ensemble mais nous devons avoué que cela prend beaucoup de temps pour une lisibilité plus que limitée.
Concepts généraux
Pour ce projet, nous avons décidé de centrer notre conception sur la visualisation plutôt que la simulation/stratégie. Ainsi, le bloc central de notre architecture sera le ChandelierGraphManager.
Diagramme de l’architecture à l’aide de paquets
Afin d’obtenir une première vision d’ensemble de notre architecture, nous vous proposons le diagramme suivant qui conserve simplement les classes majeurs et regroupe les classes mineures dans des paquets.
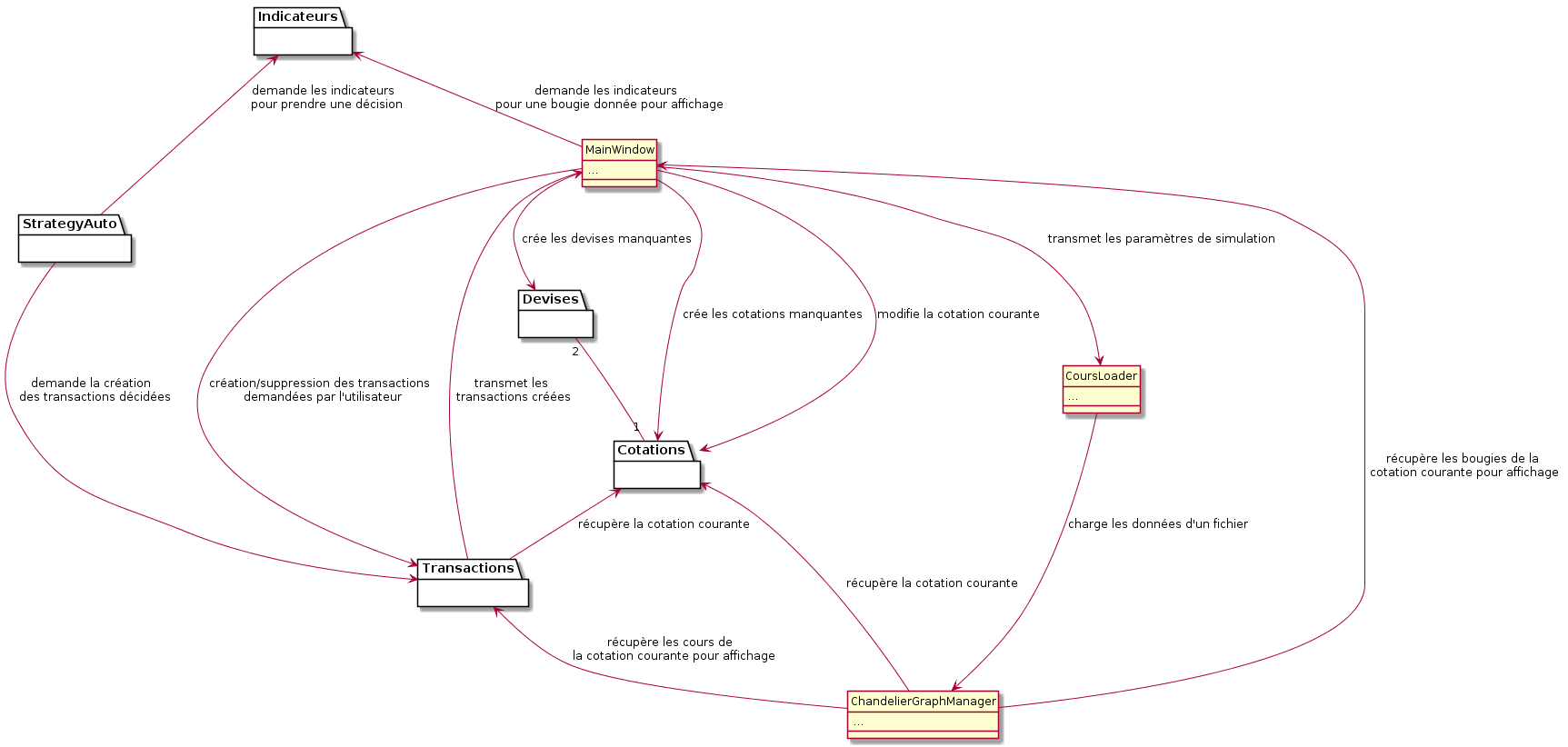
Il vous permettra d’avoir une première vision des blocs de notre architecture ainsi que des interactions qu’il existe entre ces blocs.
Les managers
Les managers seront des points très importants de notre système. Ce seront tous des singleton. Nous allons donc détailler un peu plus l’usage et l’importance de chaque manager dans notre architecture.
DeviseManager
Le DeviseManager aura deux rôles: lister les devises existantes et stocké le montant possédé de chaque devise (on fera cela à l’aide d’un map). Avant d’entrer dans plus d’explications, jetons un oeil au diagramme suivant.

Un choix particulier que nous avons fait est de dire qu’une Devise a forcément un porte-monnaie virtuel. Dans le monde réel, ce choix n’aurait aucun sens mais il faut voir notre logiciel comme un monde réduit. Ainsi, dans notre logiciel, il n’y a aucun intérêt de faire exister une monnaie sans compte en banque qui lui est lié. Dans un logiciel de simulation, une devise sans porte-monnaie est une monnaie dont l’existence peut être décrite comme inutile voire absurde.
Dans la pratique, la devise et le montant possédé seront inclus dans le DeviseManager qui possède l’attribut privé suivant:
std::map<std::shared_ptr<Devise>, qreal> m_devises;. Cette structure respecte tout à fait la représentation faite ci-dessus tout en condensant les classes. On gagné ainsi en clarté et en ligne de codes produites. Le fait de passer par un map nous évitera également quelques bugs et autres problèmes lors de nos tests.
Cette solution élégante sera également très facilement comprise ET utilisable par un développeur tiers.
Notons que nous avons évidemment coder toutes les fonctions nécessaires à l’encapsulation même si elles n’apparaissent pas sur le diagramme.
Enfin, ajoutons que nous pouvons stocker plus de deux devises à la fois car notre système laisse la possibilité de charger plusieurs cotations à la fois et donc il peut exister bien plus de deux devises dans le système. Ainsi, une devise pourra être à la fois de base dans une cotation et de contrepartie dans une autre. Cela laisse de grandes possibilités en ce qui concerne le développement de nouvelles fonctionnalités.
CotationManager
Le CotationManager a été réalisé avec une idée très proche de celle du DeviseManager. En effet, les classes qu’il devra gérer seront stockées dans le manager mais cette fois-ci avec un vector: std::vector<std::unique_ptr<Cotation>> m_cotations. Voyons son UML:
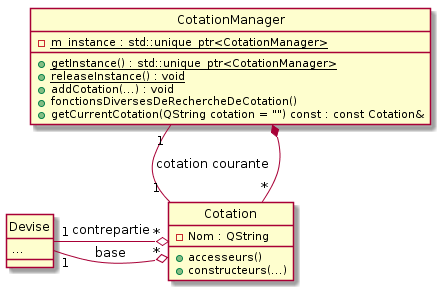
L’agrégation dans notre schéma est très importante. Nous ne créerons que les cotations existantes dans la simulation. Il peut exister deux devises dont la cotation de l’un par rapport à l’autre n’existe pas.
Le CotationManager possède énormément de fonctions permettant de faire de recherches par rapport à une des devises ou les deux. Ces fonctions sont nécessaires car elles seront énormément utilisées par d’autres blocs de notre architecture qui feront souvent appel à ce manager. Ajoutons également que créer un maximum de fonctions de recherche évitera à un futur développeur de devoir compléter cette classe.
Enfin, soulignons la présence d’une méthode permettant de récupérer la cotation courante. Cette cotation est celle affichée à l’écran. Sachant que l’utilisateur pourra charger plusieurs cotations et que le logiciel en aura une mémoire, à tout moment l’utilisateur pour passer d’une cotation à une autre. Ce sera le travail du CotationManager de retenir quelle est la cotation courante parmi toutes les cotations qu’il gère
ChandelierGraphManager
Sachant que notre architecture est entièrement centrée sur la visualisation, il semble évident que ce manager soit central. Cet élément se chargera de stocker les bougies et le cours lié à chacune de celles-ci. Pour chaque cotation existante, des bougies triées dans l’ordre chronologique seront stockées. Les autres managers et l’interface iront toujours chercher les cours dont ils ont besoin dans ce manager.
Notons que ce manager stocke tout en candleStickSet. Lorsque d’autres objets intéragiront avec lui, ils auront très rarement besoin de candleSitck. Ainsi, nous avons produit des fonctions permettant d’interfacer le ChandelierGraphManager avec d’autres classes. Pour donner un exemple concret, la méthode getCoursVector permet d’extrait un vecteur de cours d’un ensemble de bougies. Cette fonction est notamment utilisée par le TransactionManager et les indicateurs lorsqu’ils souhaitent récupérer les cours liés à une cotation.
Ce sont ces fonctions d’interfaçage qui permettent la maintenabilité du code. Nous ou de futurs développeurs n’auront pas à être contraint par les attributs du singleton ChandelierGraphManager car il existe déjà des fonctions qui permettent d’extraire les données utiles de ce manager dans différentes structures de données génériques.
TransactionManager
Ce manager a également une importance particulière car il sera le support de la stratégie qu’elle soit automatique ou manuelle. Toute transaction effectuée sera créée et stockée par ce manager; que la transaction ait été demandée par l’utilisateur ou par notre “IA” décisionnelle.
Faisons quelques remarques à propos de choix particuliers qui ont pu être faits. D’une part, on remarque que la taxe du broker est retenue par le TransactionManager. Cet objet est en quelque sorte le broker donc il semble tout à fait logique qu’il contienne cette valeur. D’autre part, on stocke les cours de la cotation actuelle dans le manager. Ce choix crée une redondance car l’information de tous les cours est déjà contenu dans le ChandlierGraphManager. Ce stockage redondant permet d’éviter de retransformer le QCandleStickSet en vector<Cours> à chaque manipulation particulière de la part du TransactionManager. La dernière transaction nous servira de curseur pour déterminer la prochaine date à traiter.
Évidemment, à chaque changement de cotation courante, il est nécessaire de réextraire un vector<Cours> donc il faudra faire bien attention à cela lors de développements futurs.
Ce singleton permettrait également de d’implémenter le mode pas à pas de la manière suivante (nous n’avons malheureusement pas eu le temps de l’implémenter):
- Lors du début de la simulation, le manager importe un vecteur ne contenant que les cours déjà passés par rapport à sa date de départ
- A chaque nouvelle décision, le
TransactionManagerimporte la bougie suivante. - En mode pas à pas, la visualisation se fera en restreignant l’affichage à la dernière date présente dans le TransactionManager.
Avec cette solution, nous n’aurons pas besoin de changer les stratégies car elles continueront de se baser sur le vecteur contenu dans TransactionManager. Il suffit juste d’ajouter des fonctions et d’en modifier quasiment aucune.
Ce manager stocke également un stack<shared_ptr<Transaction>>. Le choix de la structure stack<T> est très important car il facilitera l’annulation des dernières transactions (se trouvant forcément sur le haut de la pile).
Enfin, on constate l’existence d’un attribut m_argent_debut_simulation qui correspond au montant possédé en début de simulation. Cette valeur sera utilisée afin de calculer le retour sur investissement des transactions (ROI). Nous ne stockons pas le ROI dans les transactions car le ROI est calculé par rapport à une date donnée donc ça n’aurait pas été conceptuellement cohérent de placer le ROI dans la classe Transaction.
Importation de l’évolution d’une cotation
Un des premiers enjeux de notre logiciel était évidemment de pouvoir importer des données trouvées sur Internet. Nous préférons cela à devoir entrer à la main les données une à une.
Importation du contenu d’un fichier
Pour répondre à ce besoin, nous n’avons pas fait appel à un pattern particulier. Nous avons utilisé QFileDialog qui permet à l’utilisateur de choisir un fichier dans son ordinateur comme il en a l’habitude.
La conception n’était donc pas trop compliquée donc nous avons pu concentrer nos efforts afin de créer des fonctions qui pourront s’adapter à des fichiers aux formatages divers. Actuellement, nous traitons des fichiers de type CSV en pouvant sélectionner le séparateur à utiliser. Ce choix répond totalement aux besoins des exemples de fichiers qui nous ont été fournis.
Pour réaliser l’extraction des cours, nous utilisons deux fonctions:
CoursLoader::loadFilequi se charge d’ouvrir et de parcourir le fichier “verticalement”. Chaque ligne est envoyé à notre seconde fonction qui renvoie un cours basé sur les informations de la ligne. Elle construit un vecteur de cours qui sera lié à la cotation choisie par l’utilisateur dans leChandelierGraphManager.CoursLoader::m\_readPeriodValuequi sera chargera d’extraire un cours à partir de la ligne qui lui est envoyée.
Ce choix très simple nous permettra de simplement “surcharger” la fonction CoursLoader::m\_readPeriodValue pour pouvoir parser d’autres types de formatage de fichiers autres que CSV. Le développeur n’aura pas à changer une seule ligne de CoursLoader::loadFile.
Pour finir, soulignons que ces deux fonctions sont statiques car nous ne voyons pas le besoin d’instancier un objet spécifique pour utiliser de telles fonctions.
Choix des paramètres de simulation
Juste avant de choisir le fichier à importer, l’utilisateur aura à choisir les paramètres de la simulation.
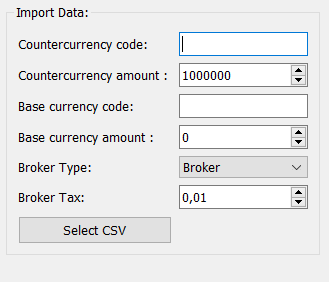
Faisons un petit résumé de ce qu’il se passera dès que l’utilisateur aura sélectionné son fichier:
- Mise à jour de la taxe du broker dans le
TransactionManagerà partir de la valeur entrée par l’utilisateur. - Vérification (dans le
DeviseManager) de l’existence des devises entrées - Création des devises inexistantes
- Mise à jour des montants possédés à partir des valeurs entrées par l’utilisateur
- Vérification (dans le
CotationManager) de l’existence de la cotation - Création si elle n’existe pas
- Importation des données du fichier dont les cours seront chargées dans le
ChandelierGraphManager, cours liés grâce à unmapà la cotation de l’étape précédente. - Mise à jour de toutes les visualisation (Porte-monnaie, graphiques, etc.)
Nous utilisons donc tous les paramètres demandés dans le sujet. On notera que les valeurs par défaut du sujet sont d’une part celles des arguments des fonctions mais également sont affichées initialement lors du lancement du programme.
Interface
Notre interface se résume à une MainWindow sur laquelle tous les éléments nécessaires au projet sont présents. Nous avons essayé de séparer au maximum cette fenêtre par bloc pour faciliter l’ajout de nouvelles fonctionnalités. Passons en revue les blocs un à un:
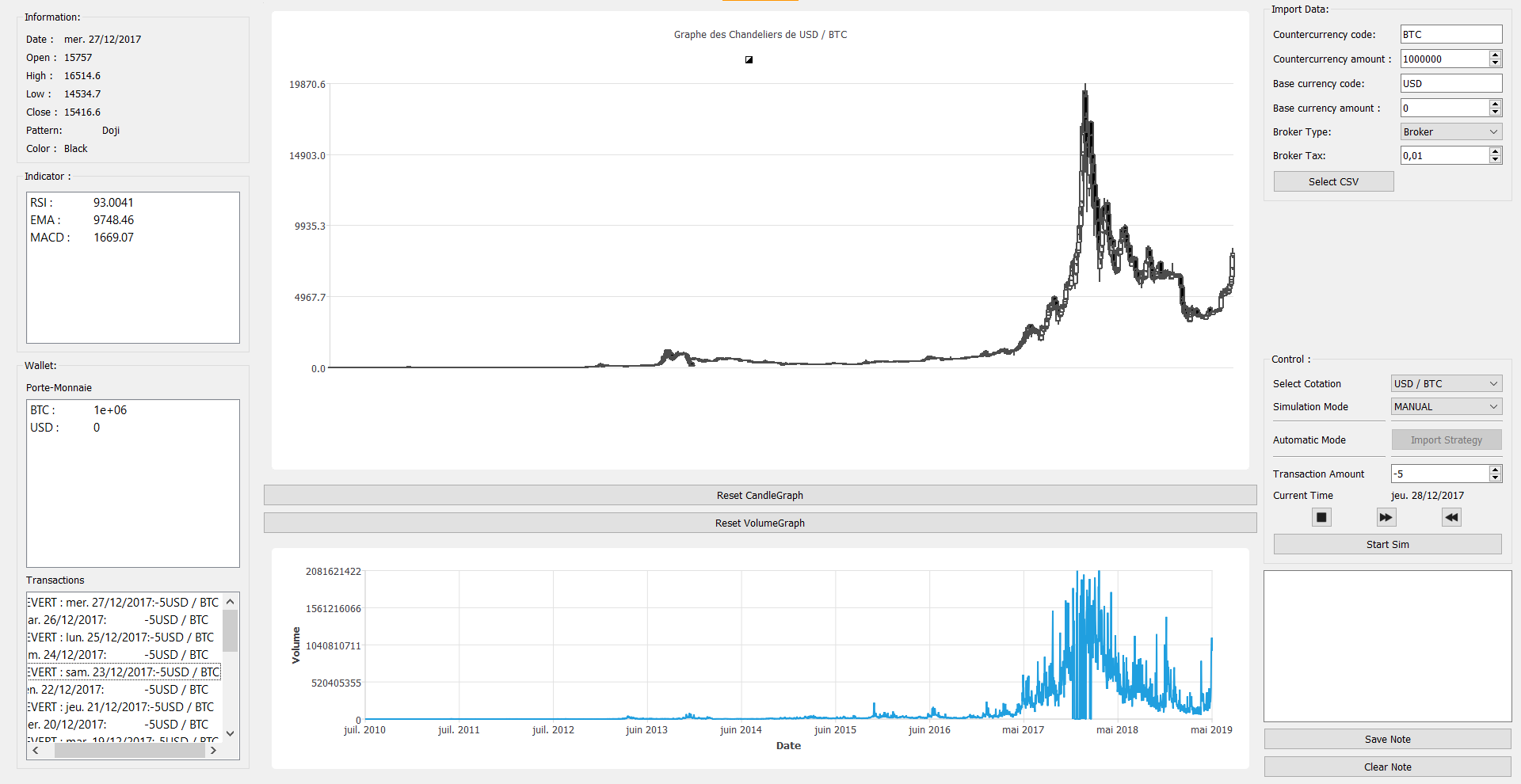
Bougie
Le bloc bougie affiche les informations relatives à la bougie sur laquelle a double-cliquée l’utilisateur. Notons que lorsqu’une transaction manuelle est effectué, l’affichage passe directement aux informations de la bougie suivante.
Indicateurs
Les indicateurs sont calculés pour la même bougie que pour la partie du dessus. Notons que certains indicateurs ont besoin d’un certain nombre de bougies précédant la bougie courante afin de calculer un indicateur. Par exemple, on ne pourra calculer aucun indicateur pour la première bougie de nos données. Cela ne fera pas crasher le logiciel, un simple message informera l’utilisateur de la raison de l’absence d’indicateur.
Wallet
Le champ n’est pas fixe car nous avons un nombre illimité de devises possibles. Le porte-monnaie affiche la valeur possédé de chaque devise au moment actuel de la simulation.
Transactions
Cet espace servira de log des transactions effectuées avec les informations demandées dans le sujet du projet (Date, Devises concernés, Montant possédé de chaque devise suite à la transaction et ROI). Notons que lors d’un retour en arrière, une ligne de “Revert” apparaîtra afin de confirmer l’annulation et de pouvoir garder une trace complète de ce qui a été tenté. Ces logs seront exportées, lors d’un exportation d’une session, avec les notes prises ainsi que le fichier de données.
Graphique en chandeliers
Il s’agit donc de la partie de visualisation des bougies dans leur ensemble. A tout moment est affiché le graphique lié à la cotation choisie dans l’espace “Control” de l’interface. L’utilisateur pourra donc passer d’un graphique à un autre s’il a charger plusieurs fichiers de données.
Pour zoomer sur une partie du graphique, il suffit de réaliser un clic gauche glissé sur la zone qui nous intéresse. Un petit bouton reset est présent sous le graphique afin de remettre à zéro le zoom (chose compliquée à faire avec le clic droit glissé qui n’est pas très ergonomique).
Graphique des volumes
Le fonctionnement est en tout point identique au graphique précédemment sauf que ce sont les volumes des cours et non plus les bougies qui sont affichés. A noter que les zooms des deux graphiques sont totalement indépendants.
Import Data
L’utilisateur peut choisir l’ensemble des paramètres de la simulation (les devises, les montants possédés, la taxe du broker). Puis il choisira le fichier à importer. Une fenêtre de sélection de fichier s’affichera pour qu’il sélectionne le fichier de son choix.
Control
Ce bloc est celui destiné à la stratégie. On peut choisir une stratégie manuelle ou une stratégie automatique. En automatique, il est possible d’importer le XML décrivant les décisions prises lors d’une session passée. En manuel, on choisit le montant positif ou négatif (achat ou vente) de la transaction.
Il faut avoir, au préalable, cliqué sur une bougie du graphique pour choisir la date de départ. Ensuite, si on clique sur le carré, toutes les transactions sont annulées et la simulation est remise à zéro. Si on clique sur les flèches à droite, une transaction manuelle ou automatique (selon le mode choisi) est effectuée et bloquée si le montant dans votre porte-monnaie ne le permet pas. Si on clique sur la double flèche pointant à gauche, on annule la dernière transaction effectuée.
La remise à zéro peut être utilisée afin de recommencer la simulation à partir d’un jour différent.
Tout au long de la simulation, la date du jour de la transaction à prendre est constamment affichée et est incrémentée à chaque transaction effectuée.
Ce bloc contient également un élément permettant de choisir laquelle des cotations, que nous avons précédemment chargées, nous voulons afficher. Ce sera sur cette cotation uniquement que porteront les transactions.
Notes
Cette partie ne demande pas énormément de description quant à son fonctionnement et son utilité.
Indicateurs
Pour cette fonctionnalité, le choix évident fut le design pattern factory. Nous avons donc conçu ce package Indicateurs de la manière suivante:
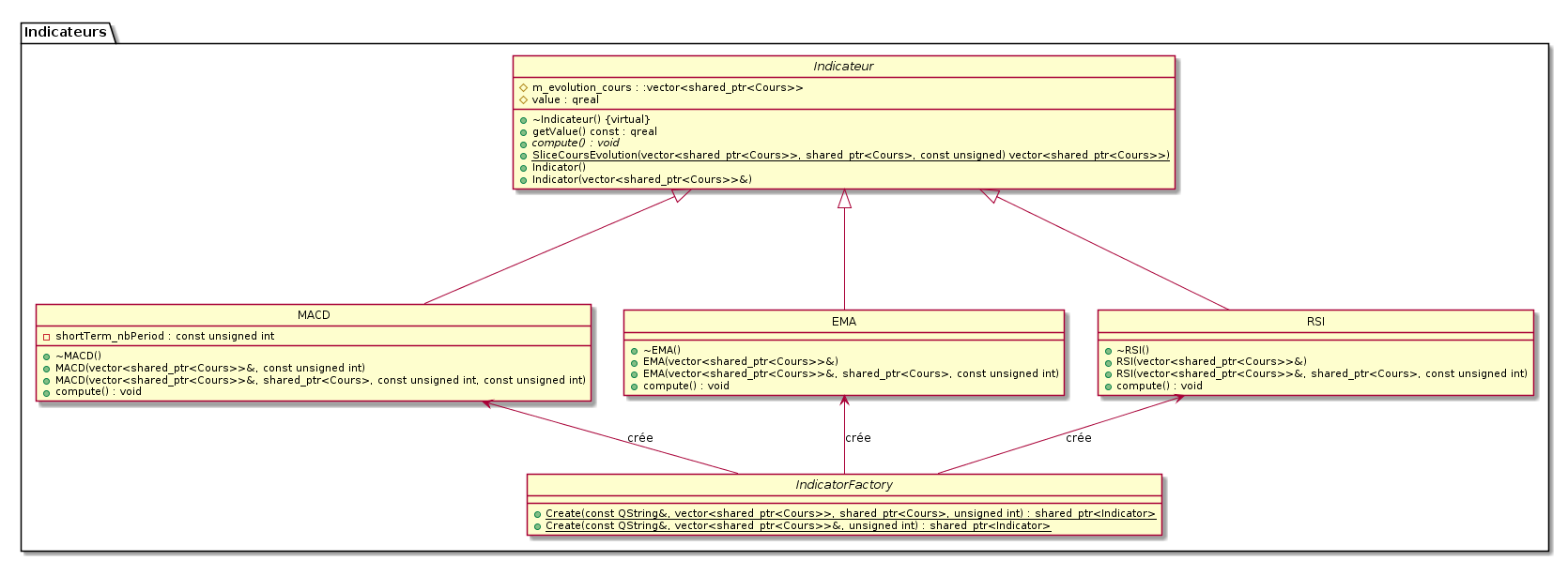
L’utilisation de ce design pattern permettra d’ajouter très simplement de nouveaux indicateurs. L’essentiel du travail à effectuer pour créer un nouveau type d’indicateur est de créer une nouvelle classe fille de Indicateur de définir sa fonction compute et ses constructeurs (ces derniers sont souvent très simples à définir) enfin il faudra ajouter un cas supplémentaire au Create de la factory. L’interface se charge déjà de calculer TOUS les indicateurs possibles lors de l’affichage des informations d’une bougie.
Adaptabilité à des évolutions futures
Soulignons quelques choix de conception. Indicateur est une classe abstraite car elle a la fonction compute virtuelle pure. Nous essayons toujours de proposer plusieurs constructeurs afin de répondre à tous les usages présents et futurs. La fonction SliceCoursEvolution est centrale pour la création de nos indicateurs car c’est elle qui permettra d’extraire les cours que nous utiliserons pour calculer la valeur des indicateurs. Notons qu’elle est très générale et qu’elle pourrait être utilisée pour d’autres usages, d’où le fait qu’elle soit statique.
Une fonction compute a été créée plutôt que d’intégrer le calcul de la valeur au constructeur car cela laisse la possibilité de modifier les cours concernés puis de recalculer l’indicateur en prenant en compte des modifications effectuées sur des bougies (sans avoir à créer un nouvelle indicateur et à re-extraire les cours qui nous intéresse). Cette possibilité n’est pas utilisée dans notre logiciel mais elle pourrait être utile lors de développement futurs.
Nous ne laissons pas la possibilité à l’utilisateur de choisir la tolérance de chacun des indicateurs. Cependant, il existe bien des arguments dans chaque constructeur d’indicateurs pour régler la tolérance (une profondeur de calcul en quelque sorte). Dans le projet actuel, nous utilisons systématiquement la valeur par défaut de ces arguments mais il est intéressant de noter qu’il est totalement envisageable de calculer des indicateurs avec une tolérance personnalisée.
Cycle de vie d’un indicateur
Les indicateurs ont une vie très courte et ont deux utilisations possibles:
- Par l’utilisateur: lors de l’affichage des informations d’une bougie, l’ensemble des indicateurs d’une bougie sont calculés puis les objets indicateurs sont détruits dès l’affichage effectué.
- Par la stratégie: la stratégie automatique produira les indicateurs dont elle a besoin pour effectuer sa décision puis pourra détruire celui-ci. Cependant, la stratégie pourra stocker dans son XML les valeurs d’indicateurs qui ont orienté son choix.
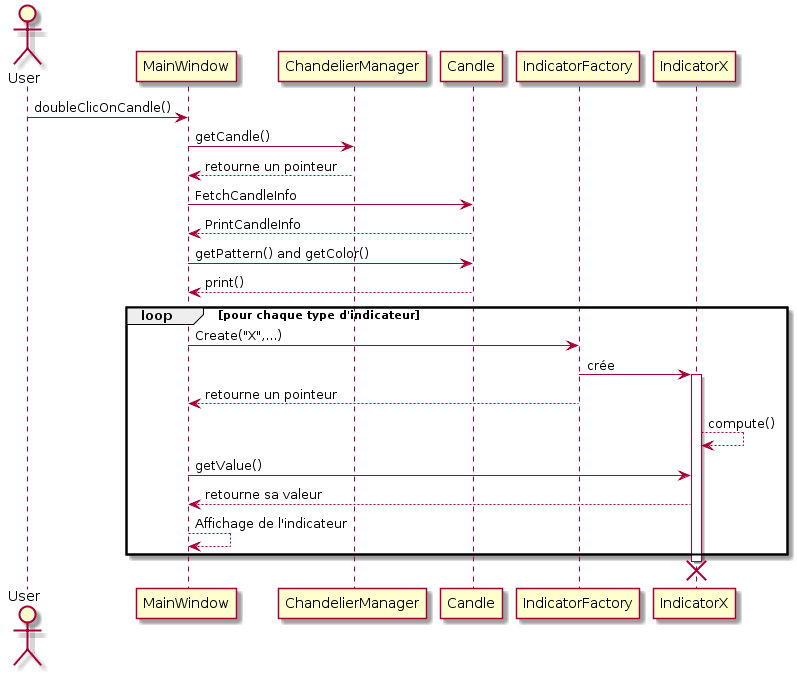
Afin de mieux cerner le premier cas d’utilisation des indicateurs, nous vous proposons le diagramme de séquence ci-dessous qui, nous l’espérons, saura traduire un peu plus formellement nos choix.
Stratégie
Mode Manuel
Ce mode fut assez simple à implémenter. La seule difficulté était de créer un curseur pointant sur le cours sujet de la prochaine transaction et de faire déplacer ce curseur convenablement.
Lorsque cela était fait, nous avions simplement à récupérer les valeurs entrées par l’utilisateur; vérifier que son porte-monnaie permet bien la transaction; créer la transaction; la placer dans notre pile de transactions. Voici un diagramme d’état synthétisant le cycle de fonctionnement de la stratégie manuelle;
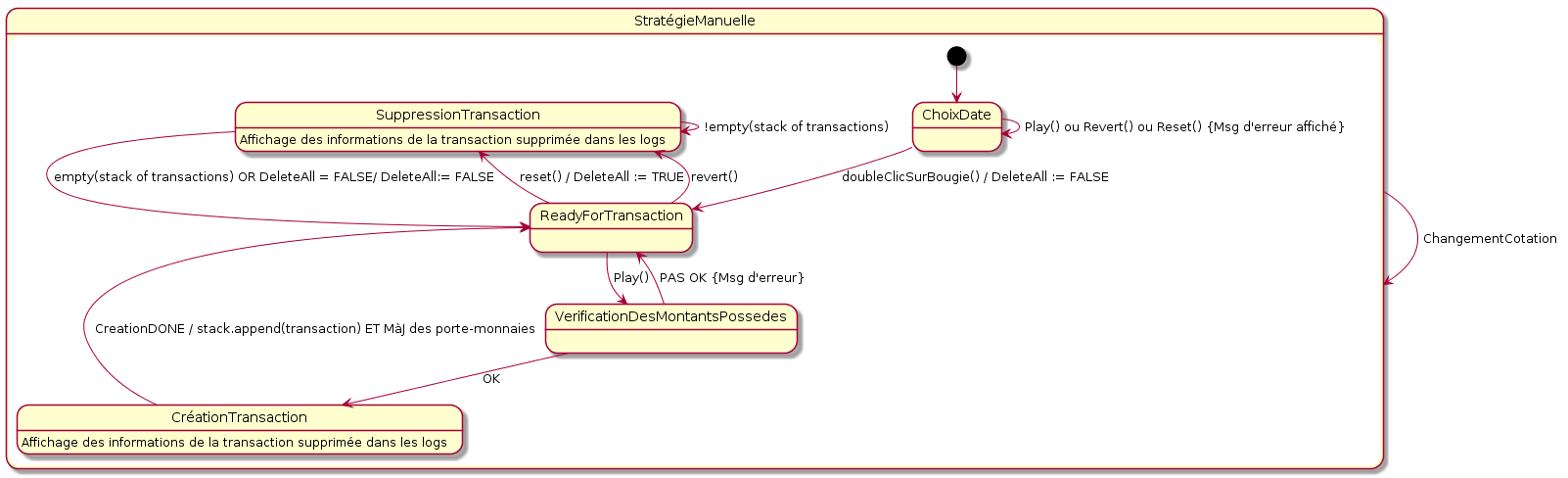
Mode Automatique
En mode stratégie automatique, c’est un algorithme écrit ou importé par l’utilisateur qui indique à un jour $J$ s’il est intéressant d’effectuer une transaction. La classe Strategy concentre toutes les informations nécessaires au bon déroulement de celle-ci. Elle a été pensée comme une machine à états, avec un état non-initialisée, état initialisée, et état simulation sur tous les jours possibles.
Afin de l’exécuter, il faut d’abord l’initialiser via la fonction Strategy::initSimulation(). Elle récupère alors le premier jour auquel on a chargé un Cours et le définit comme jour de départ. Ensuite, la fonction Strategy::nextDay() permet d’exécuter la stratégie en mode pas-à-pas : on exécute la transaction si la condition est validée, puis on passe au jour suivant. Enfin, la fonction Strategy::doAllDays() exécute la stratégie sur tous les jours auxquels des données de Cours ont été chargées.
À tout moment, il est possible d’annuler les transactions effectuées par la stratégie jusqu’un jour $J$ exclu via la fonction Strategy::cancelPreviousDays().
La condition est stockée grâce au design pattern Composite, avec pour base StrategyCondition::AbstractCondition. Cela permet d’avoir le choix entre mettre une condition concrète sur un indicateur (classe StrategyCondition::IndicatorValue), d’inverser une condition en la décorant à l’aide de StrategyCondition::Not, ou de lier plusieurs conditions entre-elles via un connecteur logique (StrategyCondition::Connector, les connecteurs et, ou, ou exclusif sont des instances de celle-ci). La façon dont c’est construit permet de facilement ajouter de nouveaux types de conditions sans avoir à modifier tous les fichier, chaque type devant redéfinir (override) les fonctions StrategyCondition::AbstractCondition::eval() (appelée pour évaluer la condition) et StrategyCondition::AbstractCondition::toXml() (appelée pour exporter la condition dans un flux XML, détaillé dans la section suivante).
Il est envisageable d’avoir une fonction permettant d’exporter un QStandartItem à ajouter dans un QStandardItemModel suivant une certaine colonne correpondant à la profondeur, et d’afficher ensuite à l’utilisateur un QtreeView dont le modèle est QStandardItemModel afin d’avoir un éditeur de stratégies visuel.
Remarque: malheureusement, ces fonctions ont été codées mais nous n’avons pas eu le temps de les relier à l’interface. Ce commentaire vaut également pour l’importation/exportation qui y est étroitement liée.
Importation/exportation
Une stratégie est importée et exportée au format XML, en appelant réciproquement les fonctions membres Strategy::openStrategy() et Strategy::saveStrategy(), prenant en paramètre un nom de fichier. Si le fichier importé est mal structuré ou ne respecte pas la convention ci-dessous, cela provoquera l’arrêt de l’application. Il y a 2 parties distinctes dans le fichier XML :
<?xml version="1.0" encoding="UTF-8"?>
<strategy>
<condition>
<indicator from="BTC" to="USD" type="RSI" op=">=" value="0"/>
</condition>
<decision from="BTC" to="USD" amount="300"/>
</strategy>
-
Balise /strategy/condition: C’est l’arbre de conditions à vérifier. Il y a 3 types de conditions possibles :
- Balise indicator (orpheline) : Permet de faire un test sur un indicateur d’une cotation, on compare si le RSI de la paire \emph{BTC/USD} est plus grand que 0. La devise de base est dans l’attribut from, la devise de contrepartie dans to, le type d’indicateur dans type, l’opérateur de comparaison dans op (attention à bien échapper les caractères
'<'et'>'), et la valeur à tester dans value. Les opérateurs pris en charges sont"<",">", pouvant être suivis de'=',"="seul, et"!="pour \og différent de\fg{}. - Balise not : Permet de d’inverser une condition enfant.
- Balises or, xor, and : Permet de connecter plusieurs conditions enfants entre-elles via un opérateur logique. Si la balise ne contient pas d’enfants, alors elle renvoie “vraie” en permanence.
- Balise indicator (orpheline) : Permet de faire un test sur un indicateur d’une cotation, on compare si le RSI de la paire \emph{BTC/USD} est plus grand que 0. La devise de base est dans l’attribut from, la devise de contrepartie dans to, le type d’indicateur dans type, l’opérateur de comparaison dans op (attention à bien échapper les caractères
-
Balise /strategy/decision: C’est les informations sur la transaction à effectuer lorsque l’arbre des conditions est validé. Elles sont décrites via les attributs suivants :
- from: Permet de spécifier la devise de base ;
- to: Permet de spécifier la devise de contrepartie ;
- amount : Quantité maximale de devises sources à convertir pour un jour donné.
Il était prévu de mettre une balise /strategy/notes, contenant du texte, afin de stocker les notes prises par l’utilisateur, mais nous n’avons pas eu le temps d’implémenter cette partie du parser XML. À noter qu’il est possible de mettre des commentaires XML uniquement directement dans la balise /strategy. Il est cependant possible de rajouter des attributs, ceux-ci seront simplement ignorés lors de l’importation.
Analyse des formes
Pour comprendre ce besoin, il faut tout d’abord se poser la question: “Qu’est ce qu’une forme pour une bougie?". Les formes ne représentent qu’une simple classification des bougies. Ainsi, une doji n’est qu’une instance de bougie ni plus ni moins (ce n’est surtout pas une classe fille ou une bougie ayant un attribut prédéfini indiquant qu’il s’agit d’une doji). Il doit alors être possible d’attribuer un type à une bougie en connaissant uniquement le cours OHLC qui lui est associé.
Notons que pour classer les bougies, nous nous appuierons sur une tolérance (ayant une valeur par défaut stockée dans le ChandelierGraphManager afin de centraliser cette valeur et de ne pas avoir d’incohérence en ayant des tolérances différentes d’une bougie à l’autre). Lors de futures améliorations de notre logiciel, cette tolérance pourrait être définie par l’utilisateur lui-même.
Afin d’un peu mieux comprendre toutes nos explications, finissons cette sous-section avec un diagramme synthétisant plus formellement nos choix de modélisation:
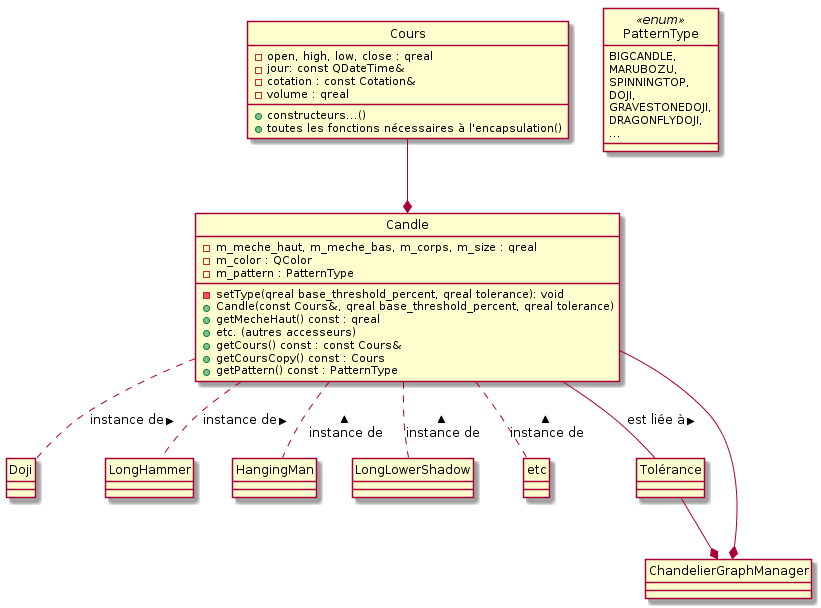
Gestion des exceptions
Afin de pouvoir débuguer plus facilement et de faciliter le développement de futurs fonctionnalités nous avons essayé de standardiser nos exceptions.
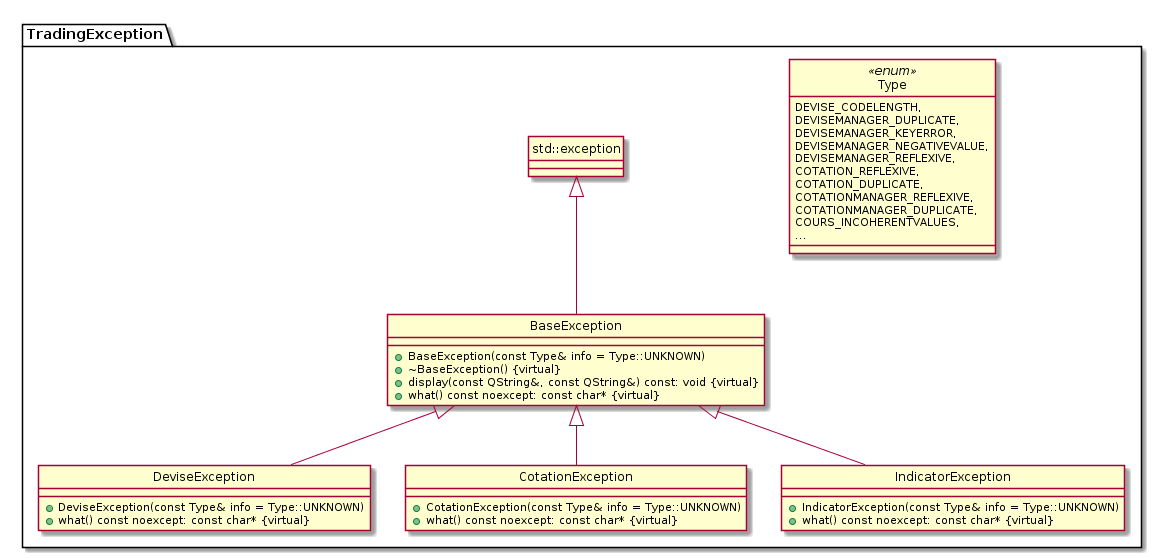
Sur ce diagramme, nous n’avons fait apparaître que 3 classes filles mais il en existe 7 différentes. De même, l’énumération Type contient en réalité près de 30 éléments.
Expliquons donc ce choix de la multiplicité à tous les niveaux. D’une part, nous essayons d’avoir un type d’exception par paquet de notre architecture afin de pouvoir mieux cibler lorsque les exceptions sont levés. Cela permet également de pouvoir attraper plus proprement et précisément nos exceptions. L’utilisation d’une enumération permet à chaque fonction de retourner un \code{what()} personnalisé selon le type de l’exception. Ainsi, une DeviseException et un IndicatorException ne retourneront pas le même message même si elles ont toutes les deux NEGATIVE_VALUE comme type.
Le projet devenant très large il était nécessaire d’avoir le plus de précisions possibles à chaque exception levée. Nous ne pouvons nous permettre de tâtonner lorsqu’il s’agit de déboggage. Quand un projet grandit et qu’il passe de main en main, il faut absolument pouvoir cibler les erreurs rapidement sans trop réfléchir et cette combinaison de multiples classes filles/énumération répond très bien à cette demande.
Le planning de l’avancement du projet
Première tentative de conception
Très rapidement après la publication du sujet, Trung et Gaëtan on produit un premier UML global qui a représenté une très bonne base travail pour la suite.
Suite à cette première conception, un repo GitLab a été initialisé avec les quelques classes fondamentales déjà établies.
Relecture et correction du premier modèle
Un peu plus tard, Marc et Alix ont fait une revue du code et surtout de l’UML et ont proposé des corrections et des ajouts aux modèles.
Des classes ont, à nouveau, été implémentées petit à petit (toutes partiellement).
Trung a également proposé une première version de l’interface (sans toutes les fonctionnalités mais donnant une idée précise de l’UI que nous pourrions adopter).
Début mai, Gaëtan a commencé a coder la structure du design pattern composite des conditions de la stratégie jusqu’au moment où l’écran de son PC principal l’a laché.
Implémentation
A quelques semaines du rendu, les choses ont accéléré. Gaëtan, qui a de nouveau un écran, s’est chargé de tout ce qui touchait à la stratégie automatique. Marc s’est occupé des indicateurs et de l’importation de données de simulation en aidant à l’intégration de ces fonctionnalités à l’interface. Alix s’est chargé de ce qui touchait aux transactions. Marc et Trung ont travaillé sur le mode manuel. Enfin, Trung a été très transversal en créant l’interface et en oeuvrant à l’intégration des divers fonctions à l’interface. Il a ainsi été la source des visualisations de notre interface et également de l’analyse de formes.
Il semble évident que nous avons tous oeuvré au développement de fonctions qui se trouvent dans les classes majeures (les managers) car nous avons tous eu besoin à un moment ou à un autre d’y ajouter des possibilités.
Débogage et livrables
Pour finir le semestre, Trung a continué d’intégrer les dernières fonctions produites à l’interface ET a contribué au débogage de ce qui devait l’être. Gaëtan a continué de développer et d’intégrer les fonctions liées à la stratégie automatique et d’écrire de la documentation. Marc a déboguer les problèmes liés aux classes qu’il connaissait le mieux (celles qu’il a développée et celles y étant fortement liées) et s’est chargé d’écrire le rapport et les diagrammes qui y sont présents. Enfin, Alix s’est chargé du débogage des problèmes liés aux transactions, de la démonstration vidéo et de l’essentiel de la documentation de nos codes.
Fonctionnalités à compléter
Tout au long de ce rapport, nous avons essayé de mettre en avant la possibilité que laissaient nos codes d’être complétés et améliorés simplement. Ainsi, nous finirons ce rapport en ouvrant la voie à quelques pistes d’améliorations possibles.
Stratégie automatique
Finir de connecter la stratégie automatique déjà codée à l’interface (tous les boutons sont déjà disponibles). Il y aura sûrement un peu de débogage à faire pour stabiliser le lien entre nos fonctions et l’interface.
Standardisation de l’exportation de stratégie
En effet, notre exportation/importation de stratégies mériterait d’être un peu retravaillée pour être plus condensée et un peu plus compréhensible par l’utilisateur.
Mode pas à pas
Nous n’avons pas eu le temps de l’implémenter mais comme dit dans la sous-section traitant du \code{TransactionManager}, il sera très facilement possible de l’implémenter sans avoir à modifier des fonctions existantes.
Stratégie multi-cotation
Sachant que notre système stocke déjà plusieurs cotations en parallèle, il est totalement envisageable de faire des prises de décision sur plusieurs cours à la fois pour un jour donné.
Interface et personnalisation
Ergonomie
Nous n’avons pas consacré un temps trop grand sur l’interface donc certains boutons pourraient être mal utilisés à cause d’une incompréhension de sa signification.
Personnalisation poussée
Nous pouvons pousser la personnalisation de la simulation plus loin en ajoutant des paramètres comme la tolérance de classification des bougies. On pourra également intégrer très simplement l’importation de fichier sur des formats autres que le CSV (en commençant par automatiquement détecter le séparateur du CSV).