Eclipse/steady — Infrastructure provisioning
It is important to note here that choices regarding the infrastructure cascade from decisions made in the implementation of the core components and the monitoring stack and not vice versa.
Kubernetes cluster creation
Creating the underlying computing and networking resources for a functional k8s cluster can be done in two distinct ways:
- Manual:
- Create the node pool on which Kubernetes will run
- Create networking resources to connect the different nodes in the same subnet
- Setup the k8s prerequisites (disable swap on all machines, install docker) via Ansible then the k8s architecture via Ansible while keeping in mind the differences between the master and worker nodes or with the kubespray tool.
- Hosted control plane: rent the control plane (etcd, metrics server) and define the node pool resources to be automatically provisioned.
The first option allows for a better control of the environment in which the cluster runs at the expense of higher overhead cost (more scripts to manage). The difficulty of creating and maintaining up-to-date and reproducible infrastructure code (even with Ansible) directly violates the lower overhead and reproductibility objectives defined above. The usage of tools such as Ansible also increases the time to spin up an instance drastically, thus, violating the goal to reduce spin up time.
Whereas, the hosted option exchanges that control for a auto-managed cluster with extra services (automated backup of the etcd server, metrics, monitoring and logging stack often external to the cluster itself). As it does not entail drawbacks that go against the objectives defined, this cluster creation method is chosen hereinafter.
Terraforming the cluster
Terraform is the tool chosen that allows use Infrastructure as Code to provision and manage any cloud, infrastructure, or service. As such, environments created with the aforementioned tool are reproducible and changes can be easily mapped out, planned and applied deterministically.
In practice, terraform “code” is a declarative JSON variant with which resources (describing a one or a group of infrastructure objects, such as virtual networks, compute instances, or higher-level components such as DNS records), providers (describing a set of resources types defined for a specific API, cloud provider, etc…) as well as variables which can reference each other. The snippet below gives an overview of a typical declaration:
provider "google" {
project = "acme-app"
region = "us-central1"
}
variable "machine_type_1" {
type = string
default = "f1-micro"
}
resource "google_compute_instance" "default" {
name = "vm_1"
# reference to the variable machine_type_1
machine_type = "${var.machine_type_1}"
zone = "us-west1-a"
}
As different cloud providers offer distinct APIs for their object creation, the Figure below illustrates the global steps in the creation of the cluster.
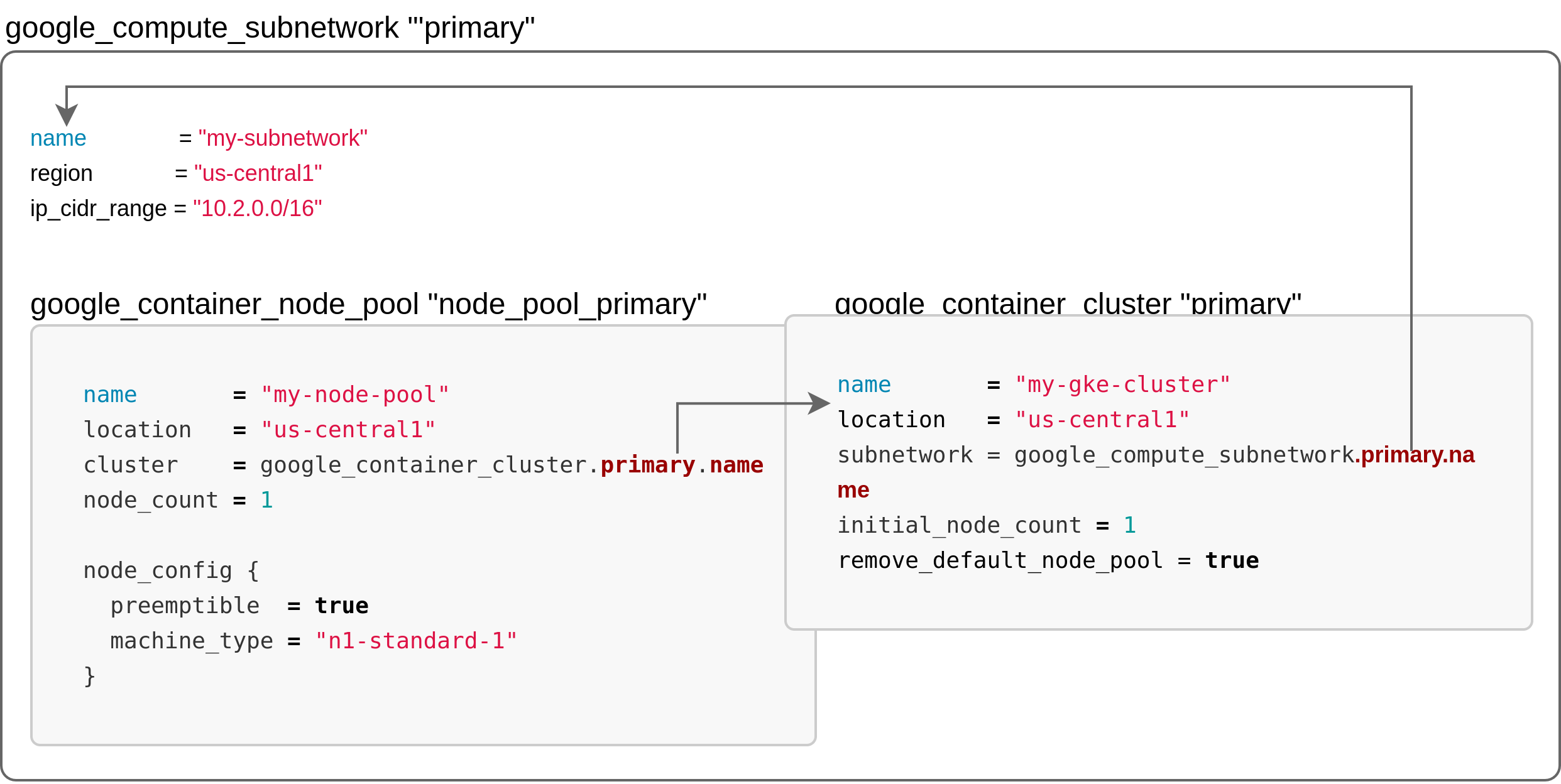
Since the order of execution of resource creation is computed by terraform, the following steps are performed. First a subnetwork is created within a given network and allocated a range of private IPs (this step, although unnecessary is preferred over using the default subnet for better isolation). Then the cluster object (control plane) is created and “nested” in the referred subnet. Finally, terraform creates the node pool without any nodes and declares it as a slave of the cluster object then spins up the amount of nodes and the appropriate resources that will be incorporated in the node pool.
Customizing the base image with Packer
On the other hand, one can create a base image with all the requirements and export it into a reusable base image. Enter Packer, an open source tool developed by Hashicorp which is uses that concept for creating identical machine images for multiple platforms from a single source configuration. Declarations consist of a set of Builders (responsible for creating machines and generating images from them for various platforms), Provisioners (to install and configure the machine image after booting) and Post-Processors (to upload, re-package artifacts).
In our use case, the base image is the Ubuntu Disco Dingo (19.04) server install image. By leveraging Packer’s boot command functionality, specific OS configurations are injected using preseeding (for instance apt setup, pre-partitioning, etc…). Then with the Ansible or Shell provisioner, the post-boot system requirements are installed. The image is then exported to the appropriate platforms defined if the build process succeeds.
Developping “PackerFiles” is a grueiling process due to the fact the VM build stage is not layered, any error would require an excruciatingly long complete rebuild. Therefore, using prebuilt templates such as Chef Bento (open source packer templates for building minimal Vagrant baseboxes for multiple platforms) is mandatory in order to maintain a decently fast workflow.