Eclipse/steady — Core components
Due to the sheer amount of components that constitute the core architecture of the tool, this section will go over the overarching themes and decisions that led to the creation of the vulnerability-assessment-tool-core helm chart.
Resource allocation
Defining resource demands for each container is mandatory in order to maintain a secure k8s deployment. The range defined on CPU and memory usage being a soft enforcement, once the limit is reached, the container is throttled and not killed, thus, ensuring both the vertical scalability of the pod and slight buffers against DDOS attacks.
The lack of a proper toolkit and data of resource usage is one of the main roadblocks in defining proper resource usages. Therefore, one has to use previous observations of the system along with general knowledge about the application’s language and frameworks used to issue a meaningful resource usage limit range.
Java and OpenJDK8
All components of the architecture are implemented in Java, specifically OpenJDK-8 which, either through fault of implementation or design flaw, more often than not has issues with memory leaks. It is therefore wise to allocate quite a bit of memory for these containers.
At the same time, container support for Java 8 is quite poor. The JVM fails to perceive the system’s resources from within the allocated docker cgroup and assumes that it is allocated the entirety of the host’s resources. It sets — by default — the maximum heap size to 1/4 of system memory and sets some thread pools size (for example for GC) to the number of physical cores. Consequently, containers often go over resource limits and lead to them being OOM (out of memory) killed.
The openjdk:8u212 image resolves this issue by integrating the back-ported Docker support. It is therefore mandatory to switch the base image to a subsequent tag. Further fine tuning can be done via environment flags such as -XX:InitialRAMPercentage which require an in heap depth profiling of each container which we’ll no explore further.
Frameworks and Workload
Thanks to data collected by the “old” monitoring stack, average and peak CPU and memory usage are available and can be extrapolated to fit with the k8s deployment.
Persistent caches
Some applications benefit greatly from having a shared cache between different replicas. For instance, the rest-lib-utils often clones git repositories locally in a cache directory, an operation which should not be done by every container. This cache directory can then be shared between replicas to avoid the redundant operations. However ReadWriteMany volumes are not offered by any cloud provider and should be self provisioned.
Before attempting to implement any shared filesystem solution, it is important to establish whether or not the computation cost and communication cost between nodes is lower than the cost of running the operation redundantly on each node. Although the theoretical approach of estimating the complexity of the previously mentioned costs is more sound. In practice, it is impossible to establish such a measure and more viable to run a benchmark of both deployments. The proposed benchmark consists of running the patch-lib-analyzer cronjob against the rest-lib-utils containers to load and find vulnerable constructs for 1024 CVEs. Due to time constraints, this benchmark is not run multiple times. On the single sample observed, the shared file system solution (NFS) yield an approximately 12% lower execution time than its counterpart. With this positive result, a couple options for provisioning ReadWriteMany volumes are possible;
NFS (Network File System)
NFS is a distributed file system protocol which allows remote hosts to mount file systems over a network and interact with those file systems as though they are mounted locally. NFSv2 and NFSv3 can both use TCP or UDP running over an IP Network. Although stateless UDP connection translate into better performance on clean, non-congested networks (often the case in intra-cluster network) thanks to lower protocol overhead, using TCP increase reliability and offer better error detection as to not overload the network. Going forward with using TCP, the protocol (v2 and v3) uses RPC (remote protocol calls) to request a service from the host machine over the network and therefore require the portmapper (utility to map RPC services to the ports they are listening on), the mountd (daemon implementing the NFS MOUNT protocol) ports to be exposed as well as the nfs protocol ports to be exposed to the network.
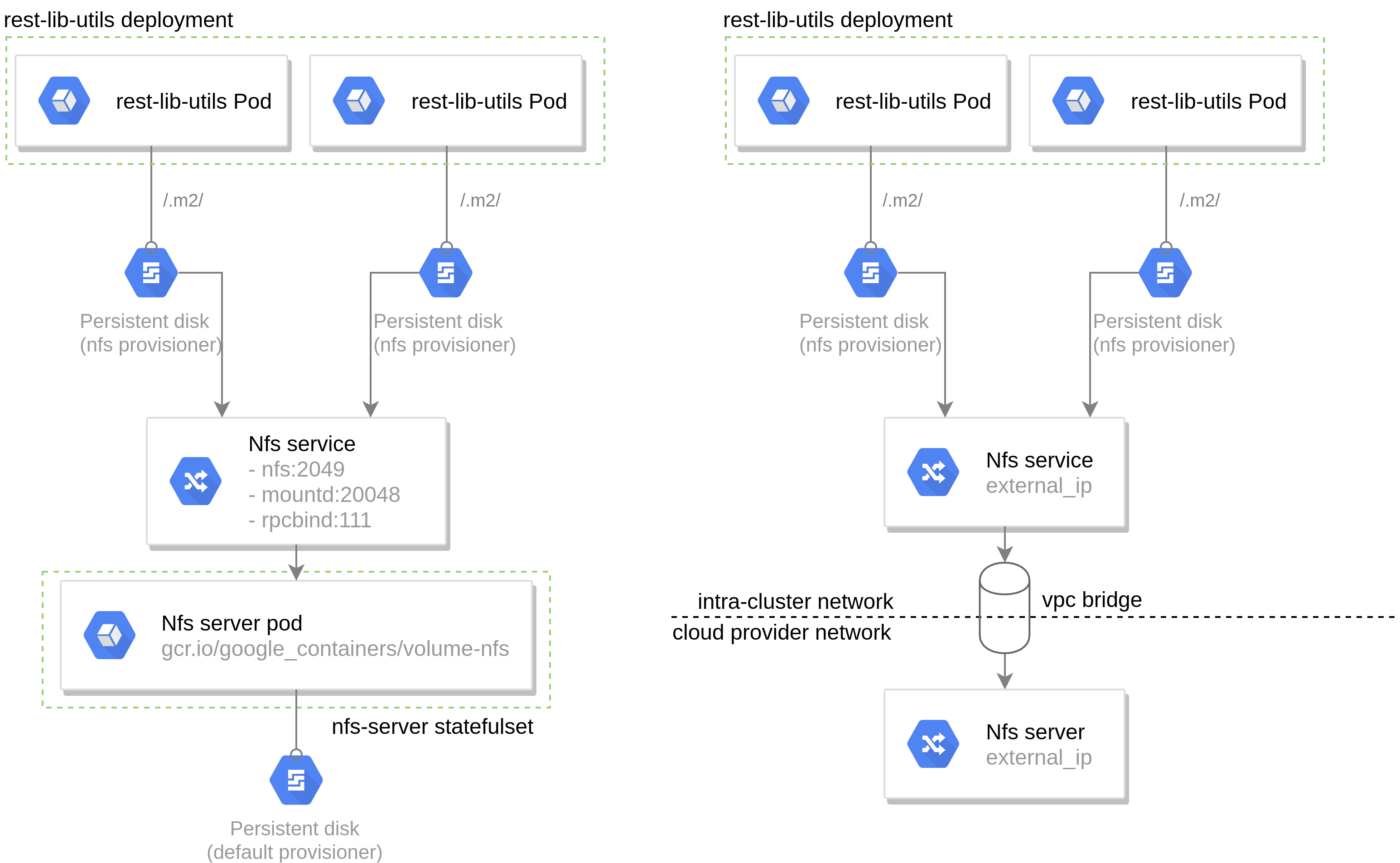
In the case of rest-lib-utils component, the cache directory can be served over a network, allowing concurrent access from multiple containers. Deployment an NFS provisioner in a k8s context can be done either by leveraging k8s functionalities or by leveraging the underlying Cloud Provider functionalities.
A k8s native NFS provisioner would require an nfs-server deployment (with a single replica) mounting a PVC backed by a PV provisioned by the default provisioner which is served through a clusterIP service exposing the ports previously mentioned .
The cloud provider based deployment is similar, although the NFS service is an ExternalName pointing to the hosted NFS server. However, in most providers, the cluster network is not within the same subnet as the NFS one, therefore a VPC bridge (with the appropriate networking rules) is required for this setup to properly function.
CIFS (Common Internet File System)
This protocol is chattier NFS and is more adapted to mixed client environments (Windows and Unix hosts). Since the cluster is made up of Unix only clients, this option is not chosen.
Ceph Storage Cluster
Ceph is a distributed filesystem which unlike NFS also defines how data is stored and served. Deploying the Ceph Storage cluster requires the following components:
- Monitors: component that maintains the map of the cluster state.
- Managers: keeps track of runtime metrics
- Ceph OSDs: object storage daemons that handle data storage, replication, recovery, re-balancing, etc…
- MSDs: metadata storage for the filesystem
Due to the complexity of its installation and numerous components, Ceph is usually installed with Rook (an operator meant to simplify storage orchestration in k8s) to create a provisioner for ReadWriteMany volumes. Through the Rook abstraction, an application can then issue a ReadWriteMany volume claim with the appropriate storage class (Block Storage in this case) and the Ceph Storage Cluster would be the provisioner backing said claim.
Despite the scalability and abstraction provided by this architecture, the cache data stored is not critical enough to warrant replication and the overhead cost of this system would overshadow the benefits of the cache. Therefore, cache data storage would be done using NFS.